


البيانات الضخمة Big data مصطلح بدأ بالانتشار خلال السنوات القليلة الماضية, تكمن اهمية هذا المجال بالعوائد الطبية و الاقتصادية و الأمنية الهائلة التي يمكن الحصول عليها عن طريق تحليل البيانات الضخمة المتوفرة حاليا.
حسب تقرير لشركة سيسكو الشهيرة, سيتم نقل اكثر من 1000 اكسابايت بنهاية عام 2016 و اكثر من 2300 اكسابايت بنهاية 2020. ما يعادل اكثر من 2.3 مليار جيجابايت سنويا.
اذاً, ما الذي يجعل معالجة البيانات الضخمة يختلف كثيرا عن معالجة البيانات العادية ؟
عادة تتم معالجة وتخزين البيانات العادية عن طريق منصات قواعد البيانات, حيث تكون هذه البيانات معروفة الشكل و النوع و المصدر, لذلك يسهل التعامل معها باستخدام الادوات المتاحة.
أما البيانات الضخمة فتملك عدة سمات مختلفة عرفها الباحثون و تم الاتفاق على تسميتها مجموعة ال Vs نظرا لان كل منها يبدأ بحرف ال V في اللغة الانجليزية, في هذه التدوينة سنتطرق لثلاثة من أهم هذه السمات و هي :
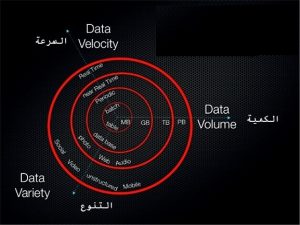
1- سرعة البيانات Velocity: ومنها المعالجة الفورية للبيانات واصدار استنتاجات بدون تخزينها. ومن تطبيقاتها التنبؤ السريع بالزلازل و الفياضانات عبر تحليل مؤشرات الطقس فورياً.
2- كمية البيانات Volume: حيث يتم معالجة بيانات حجمها كبير جدا مثل بيانات مكتبة الكونجرس الامريكي والتي تحتوي على ملايين الكتب و الوثائق.
3- تنوع البيانات Variety: وهو دمج وتحليل البيانات من عدة مصادر مختلفة سواء كانت منظمة أو غير منظمة, مثال على ذلك مشروع جوجل للانذار بالامراض المعدية حيث يقوم بتحليل قواعد البيانات التقليدية مع تغريدات و كلمات البحث و المعلومات الجغرافية و كتابات متناثرة عشوائية من هنا و هناك, بهدف التنبؤ بظهور الامراض في مكان ما !
بالطبع يوجد للبيانات الضخمة سمات أخرى تصل الى 7. لكن قد تكون هذه هي السمات الابرز للتفريق بين مشاريع البيانات الضخمة عن غيرها.
أما بالنسبة لكيفية الاستفادة من مشاريع البيانات الضخمة فسيتم التطرق لها في تدوينه لاحقة باذن الله.
د. أسامة الجميلي

{kind=link}